系统如何生成永不重复的ID
在现代互联网业务系统中,各种业务场景都需要生成唯一标识符,比如支付系统中的交易ID、退款ID等。那么在分布式系统环境中,我们应该如何选择合适的ID生成方案呢?下面将详细介绍几种常见的解决方案,希望能为您的技术选型提供参考。
一个合格的分布式ID应该具备以下特征:
- 全局唯一性:确保在整个分布式系统中生成的ID都是唯一的
- 趋势递增:保证ID在一定程度上有序递增,有利于数据库性能
- 高可用性:确保在任何情况下都能正常生成ID
- 时间信息:ID中最好包含时间戳信息,便于排查问题和数据分析
基于系统时间戳
利用当前系统时间的毫秒数,结合业务属性、用户信息、随机数等要素组合生成ID。这种方式能保证唯一性,但难以保证严格的有序性,要实现有序性需要依赖数据库或其他存储介质。
UUID通用唯一标识符
Java标准库提供了生成UUID的方法,可以产生32位的唯一随机字符串。UUID的唯一性毋庸置疑,足够使用很多年,但缺点是缺乏时间信息、业务可读性差,且无法保证有序递增。
这种方式实现简单、效率高,但在实际业务系统中较少采用。
数据库自增序列
通过数据库的自增主键特性来生成ID,利用数据库自身的递增机制保证ID的唯一性和有序性。
这种方案实现简单,但强依赖于数据库系统。在进行分库分表或数据迁移时,会面临很大挑战。
因此,这种方案不太适合分布式场景。
批量ID预生成
一次性批量生成多个ID,减少数据库访问频率。每次生成都需要更新数据库中的最大ID值,并在内存中维护当前可用的ID范围。
这种方案存在单点故障风险,服务重启可能导致ID不连续。同时,也不利于系统的水平扩展。
基于中间件生成
利用Redis的单线程特性,使用INCR命令实现原子性自增操作,从而生成唯一有序的ID。
这种方式不依赖传统数据库,性能较好。但需要引入Redis中间件,增加系统复杂度。即使已有Redis基础设施,高频的ID生成请求也可能对Redis性能产生影响。
还可以使用Zookeeper的znode版本号或MongoDB的ObjectId等机制,但一般不推荐使用中间件来生成ID。
Snowflake雪花算法
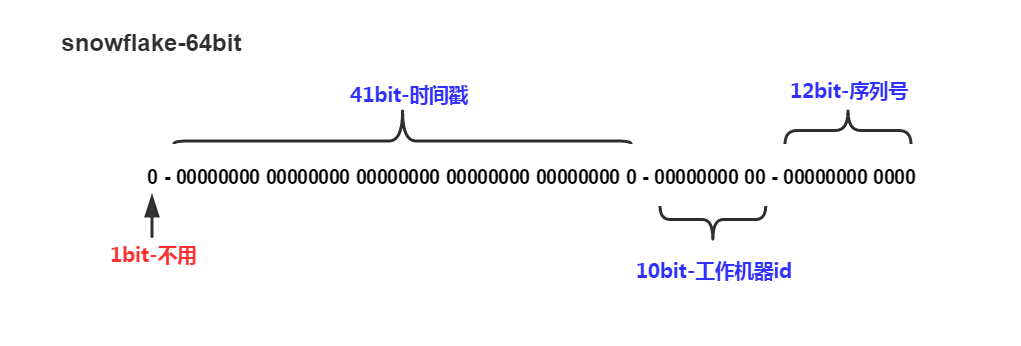
如图所示,Twitter的Snowflake算法包含以下几个部分:
- 41位时间戳,精确到毫秒,可用69年
- 10位机器标识,最多支持1024个节点
- 12位序列号,每个节点每毫秒可生成4096个ID
- 最高位为符号位,固定为0
这种方案性能优异,在单机上保证递增。但在分布式环境中,由于各节点时钟可能存在偏差,无法保证绝对的全局递增。
虽然该项目已于2010年停止维护,但其设计思路被许多ID生成器借鉴和改良。
百度UidGenerator
UidGenerator是百度开源的分布式ID生成器,基于Snowflake算法改进而来,整体表现不错。但国内开源项目的长期维护性值得关注。
具体使用方式参考:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
美团Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一、趋势递增、信息安全等特性。文档中详细对比了多种分布式方案,但需要依赖数据库、Zookeeper等中间件。
具体信息参考官网:
以上就是常见的分布式ID生成方案,不同的业务场景需要选择适合的方案。如果您有更好的解决方案,欢迎在评论区分享讨论。