Java日志体系全解:从框架选型到最佳实践
日志是程序的“黑匣子”,它忠实记录运行轨迹,是在生产环境诊断问题、分析性能、审计行为的核心工具。掌握正确的日志技术栈与输出规范,是每一位后端开发者的必备技能。
Java日志技术演进史
市场上存在多个日志相关的Jar包,常让人混淆。它们的关系可概括为“门面”与“实现”。
Java Util Logging (JUL):
JDK 1.5自带的日志框架,位于 java.util.logging 包。功能较为基础,在开源生态中不占主流。
官方指南:https://docs.oracle.com/javase/8/docs/technotes/guides/logging/overview.html
Log4j 1.x:
Apache旗下的经典日志实现框架,曾统治市场多年。因其架构老旧,已于2015年停止维护。
官方已建议迁移至Log4j 2。
Log4j 2.x:
Log4j的完全重写版本,在性能、异步日志、插件体系上大幅提升,是强有力的竞争者。
官网:https://logging.apache.org/log4j/2.x/
Commons Logging (JCL):
Apache提供的早期日志门面。应用程序通过JCL接口编写日志,运行时再绑定具体的实现(如Log4j)。这解决了与具体实现的耦合问题。
SLF4J (Simple Logging Facade for Java):
当前最主流的日志门面。它提供了更好的API设计(如占位符{}),并且设计了完善的桥接方案,可以对接几乎任何旧的日志框架,是“日志统一”的事实标准。
Logback:
由Log4j创始人亲手打造,作为SLF4J的原生实现。它在性能(异步日志损耗更低)、配置(支持XML和Groovy)、功能(如条件过滤)上优于Log4j
1.x,是当前与SLF4J搭配的黄金组合。
官网:https://logback.qos.ch/
迁移理由:http://www.oschina.net/translate/reasons-to-prefer-logbak-over-log4j
如何选择你的日志组合?
首选推荐:SLF4J + Logback
性能优异,API友好,生态融合好,是大多数新项目的起点。
备选方案:SLF4J + Log4j 2
如果需要Log4j 2的某些高级特性(如更精细的异步日志器配置),这也是一个高性能组合。
历史项目:可能会看到 Commons Logging + Log4j 1.x,应考虑逐步迁移。
关系图示:SLF4J强大的适配能力,使其能够统一项目中各种日志API的调用。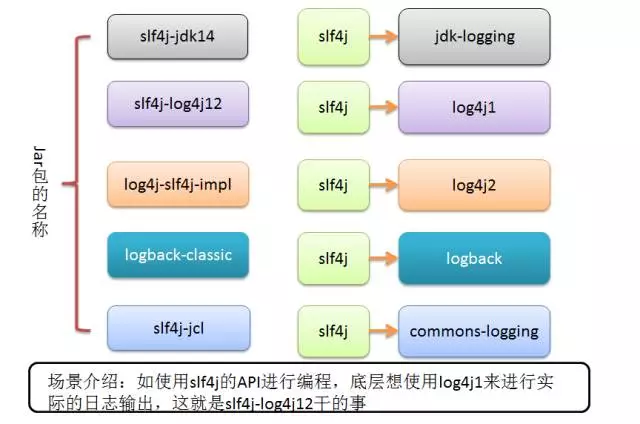
日志级别:定义信息的重要性
日志级别是过滤信息的关键。以Log4j/Logback为例,级别从细到粗(输出从多到少)通常为:
TRACE < DEBUG < INFO < WARN < ERROR
更极端的还有:
FATAL:严重错误,可能导致应用中止。
OFF:关闭所有日志。
ALL:启用所有级别。
核心规则:日志记录器有一个生效级别(Threshold)。只有等于或高于该级别的日志语句才会被实际输出。例如,若级别设为INFO,则DEBUG和TRACE日志将被静默忽略。
级别选择可视化: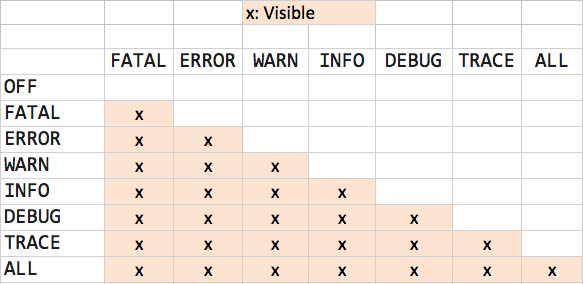
阿里巴巴《Java开发手册》日志规约精要
阿里巴巴的规范为我们提供了极佳的实践指南:
其核心思想包括:应用中使用日志门面(SLF4J)、避免日志重复打印、确保日志内容简洁明确且包含上下文、谨慎记录敏感信息等。
编写日志代码的正确姿势
- 正确定义日志对象
java
// 推荐:面向接口编程,使用SLF4J的Logger
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger LOGGER = LoggerFactory.getLogger(YourClass.class);
- 使用参数化占位符
SLF4J的{}占位符方式,可避免不必要的字符串拼接,提升性能。
java
// 好:清晰、高效
LOGGER.info(“订单[{}]创建成功,用户:[{}]”, orderId, userId);
// 避免:在日志关闭时仍进行字符串拼接
LOGGER.info(“订单” + orderId + “创建成功,用户:” + userId);
- 为不同场景选择合适的级别
ERROR:记录业务异常或系统错误,需人工干预。
WARN:记录预期内的异常或可疑情况,如参数格式错误,但不影响核心流程。
INFO:记录关键业务流程节点、系统状态变化。这是生产环境通常设置的基线级别。
DEBUG:记录详细的调试信息,如方法入参、中间结果。仅在开发/测试环境开启。
TRACE:记录最细致的执行轨迹,性能开销最大。
必须杜绝的八大错误日志实践
禁用 System.out/err.println:无法纳入日志管理体系,输出目的地不可控。
禁用 e.printStackTrace():同上,且输出格式混乱。
避免日志与异常重复抛出:在catch块中记录了错误日志,就不要再将原异常抛出,否则会导致日志重复。
不要依赖具体实现类:应始终使用org.slf4j.Logger,而非ch.qos.logback.classic.Logger。
记录完整的异常堆栈:使用logger.error(“描述”, exception),而非exception.getMessage()。
勿用错日志级别:错误(ERROR)不能用信息(INFO)级别记录,否则在查看错误日志时会遗漏。
避免在循环热点中打印日志:高频循环内打印日志会迅速产生大量IO,严重拖慢程序。应在循环外总结性输出。
生产环境严禁开启DEBUG:DEBUG日志量巨大,会迅速写满磁盘,并产生极高IO负载,导致服务瘫痪。
遵循以上原则,你的应用日志将成为运维和开发的得力助手,而非负担。