企业级消息中间件选型策略与核心考量
在构建现代化分布式系统时,消息中间件扮演着至关重要的“中枢神经”角色。面对市场上 ActiveMQ、RabbitMQ、RocketMQ、Kafka
等众多优秀开源方案,如何做出符合自身业务与技术栈的明智选择,成为架构师的核心课题之一。
明确选型评估维度
一个全面的选型评估应覆盖以下多个维度,而非仅比较单一性能指标:
社区生态与活跃度:开源项目的生命力体现在其社区贡献、版本迭代频率、问题响应速度上,这直接关系到长期使用的可持续性和获取支持的难易度。
功能特性完备性:包括对消息持久化、事务消息、顺序消息、死信队列、延迟消息、消息回溯等高级特性的支持程度。
性能与扩展性:主要考察吞吐量(TPS/QPS)、延迟(Latency)以及通过增加节点实现线性扩展的能力,这决定了系统处理海量数据流的潜力。
可靠性与数据一致性:消息传递的可靠性保证(如“至少一次”、“仅一次”语义)、多副本机制、故障自动转移(Failover)能力。
运维复杂度与监控:集群部署、配置管理、监控指标(如堆积情况、消费延迟)的完备性,以及是否提供友好的管理控制台。
技术栈融合度:与现有开发框架(如 Spring)、编程语言、上下游生态(如流处理框架、数据湖)的集成是否顺畅。
主流产品横向对比分析
(以下分析基于特定版本的一般特性,实际表现需结合具体场景验证)
Apache ActiveMQ
优势:历史悠久,属于 JMS 规范实现,与 Java EE 生态结合紧密,支持多种协议(AMQP, MQTT, STOMP等)。
不足:在超高吞吐量场景下性能可能成为瓶颈,社区活跃度相对较新秀有所下降。
RabbitMQ
优势:基于 Erlang/OTP 平台,实现优雅,在消息路由(灵活的路由规则)、可靠性、管理界面方面表现出色,是传统企业消息场景的稳健选择。
不足:当消息堆积严重时,性能下降较明显;集群扩展相对复杂,镜像队列模式对网络要求较高。
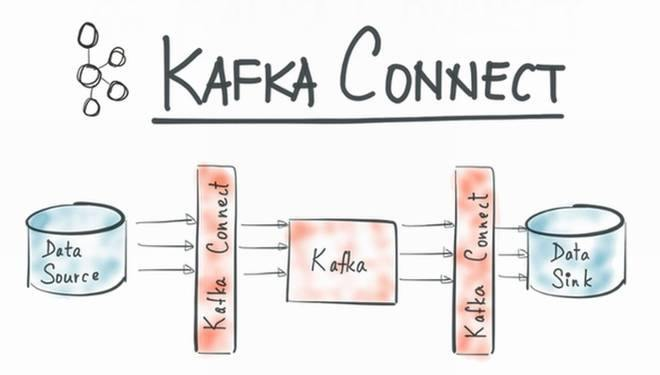
Apache Kafka
优势:为高吞吐、持久化日志场景而生。采用顺序读写磁盘、零拷贝等技术,吞吐量极高。分区和消费者组模型天然适合水平扩展和流式数据处理,与大数据生态无缝对接。
不足:早期版本在事务消息、全局顺序消息等方面功能较弱(新版已增强),功能复杂度高,运维需要更多专业知识。
Apache RocketMQ / Alibaba Cloud MQ
优势:脱胎于阿里巴巴的双十一场景,在保证高吞吐的同时,提供了强一致的事务消息、顺序消息、定时/延时消息等丰富功能。中文文档和社区支持对国内开发者友好。
不足:国际化社区相对较小。
决策框架与最终建议
第一步:明确核心业务场景
日志收集、流式数据处理、事件溯源:Kafka 几乎是标准答案,其日志存储模型和生态优势明显。
复杂的业务消息路由、企业应用集成(EAI):RabbitMQ 的灵活路由和可靠性是强项。
金融交易、电商订单等需要强事务保证的场景:RocketMQ 提供了成熟的事务解决方案。
遗留系统改造、遵循 JMS 规范:ActiveMQ 或 RabbitMQ(通过插件)可能是更平滑的迁移路径。
第二步:评估团队与运维能力
团队是否熟悉 Erlang?运维 RabbitMQ 集群需要一定经验。
团队是否有大数据背景或愿意投入学习?Kafka 的运维和调优门槛相对较高。
RocketMQ 的 Java 实现和中文文档对国内团队可能更友好。
第三步:进行概念验证(PoC)
对于备选的 1-2 个方案,搭建测试环境,模拟真实业务流量(包括峰值和异常情况),从性能、稳定性、功能、运维操作四个方面进行实测。
结论
没有“最好”的消息中间件,只有“最合适”的。对于大多数新兴的互联网高并发、大数据场景,Kafka
因其卓越的吞吐量、可扩展性和成熟的流处理生态,正成为越来越多架构的首选。而对于传统企业应用、需要复杂路由和强事务的业务,RabbitMQ
和 RocketMQ 则是强有力的竞争者。选型的本质是在功能、性能、复杂度与团队能力之间找到最佳平衡点。